
Fast Barrier for x86 Platforms
What is it?
We implement fast barriers for x86-compatible multicore processors. We in particular target Intel's Core2 Duo and Core2 Extreme, their latest dualcore and 2x dualcore processors.
A few comments:
- The barrier is intended for use in a high-performance computing environment: A single program multiple data (SPMD) programming model with one thread per processor; the thread owns the processor "exclusively."
- We use thread affinity to ensure this usage model.
- We support pthreads (Linux) or Windows threads as threading libraries.
- The barrier is implemented using busy waiting, without a call to the threading library or the operating system.
- The barrier is intended for experiments – it comes with many implementation options and special cases.
- We used Intel C++ compiler syntax and VisualStudio .NET 2003 and are in the process of porting it to gcc + make.
- It is all in C. No assembly code is used.
Motivation
To fully exploit current multicore processors and parallelize even small, tightly coupled problems, extremely light-weight synchronization is a must. It turns out that using synchronization primitives provided by threading libraries, the operating system, and even x86 lock instructions are much too expensive to take real advantage of the new multicore processors. Using our own synchronization implementation, we succeeded speeding up very small workloads: For instance, on a Core2 Duo we see first parallel speed-up for an FFT of size 1024, which runs for approximately 10,000 cycles and the working set fits fully into the L1 data cache of one core.
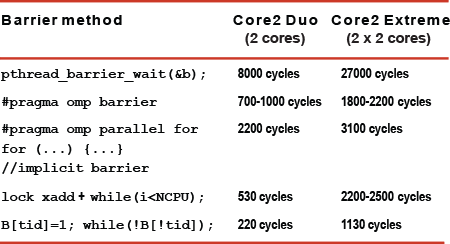
Speed
We compared multiple fast barrier variants. The base line is the (fast) OpenMP barrier of the Intel C++ compiler. A OS-based or pthreads barrier takes on the order of 10,000s of cycles.
- pthreads barrier
- OpenMP explicit barrier by the Intel C++ compiler.
- OpenMP implicit barrier by the Intel C++ compiler.
- an implementation based on the lock xadd instruction.
- our lock-instruction free NUMA implementation.
Download
Barrier. zip (12 KB). The zip file contains a VisualStudio .NET 2003 + Intel C++ Compiler 9.1 project that implements a small threading interface to pthreads/winthreads, the barrier, affinity, timing, and a small correctness/timing program.
| rdtsc.h | timing interface, using the RDTSC instruction |
| smp.h, smp.c | the actual barrier implementation |
| threads.h | threading interface to pthreads and winthreads |
| main.c | example and test program |
| barrier.sln | VisualStudio .NET 2003 solution file |
| spmd.vcproj | VisualStudio .NET 2003 project file |
| spmd.icproj | Intel C++ compiler 9.1 project file |
The following parameters control the behavior of the barrier implementation and the test program.
| CHECK_RUNS | number of runs in the correctness check |
| MEASURE_RUNS | number of runs in the timing |
| FASTBARRIER | use the fast, specialized implementation, instead of the lock xadd variant |
| NUMABARRIER | use the tree-based barrier instead of the flat barrier for 4 processors (targets Core2 Extreme) |
| SAFETY | turns on the pause and mfence instruction for memory consistency paranoia |
| CACHELINE | length of the cache line |
| D21, D22, D41, D42 | magic numbers to put data in good cache line locations |
References
For more information please email Franz Franchetti, franzf (at) ece.cmu.edu.