
Self-adaptive Sorting Library
What is it?
A sorting library that adapts itself to platform characteristics and to the structure or statistics to the input to achieve better performance.
Overview
Sorting presents a new challenge for library generators, namely that the relative performance of the algorithms depend not only on the characteristics of the target machine and the size of the input data but also on the distribution of values in the input data set. Our goal was to generate automatically high performance routines that automatically adapt to widely different architectural features and input characteristics. We solved this problem by developing machine learning techniques to extend empirical search to the code selection and the code synthesis of sorting routines.
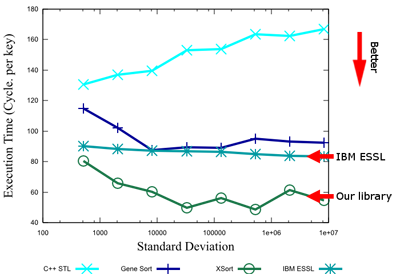
In our first effort [2], we generate sorting routines that dynamically adapt to the characteristics of the input data by selecting the best sorting algorithm from a small set of alternatives. To generate the run time selection mechanism our generator makes use of machine learning to predict the best algorithm as a function of the characteristics of the input data set and the performance of the different algorithms on the target machine. This prediction is based on the data obtained through empirical search at installation time. Our results show that our approach is quite effective. When sorting data inputs of 12M keys with various standard deviations, our adaptive approach selected the best algorithm for all the input data sets and all platforms that we tried in our experiments. The wrong decision could have introduced a performance degradation of up to 133%, with an average value of 44%.
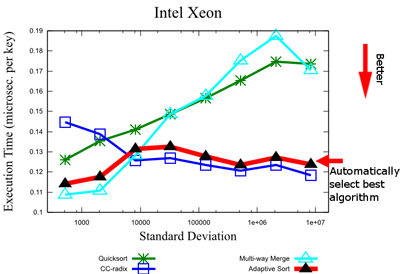
Our previous study selects a "pure" sorting algorithm at the outset of the computation as a function of the standard deviation. We continue to explore in [1] if a hybrid sorting routine can further improve performance and how to generate an efficient hybrid sorting routine. Our approach uses genetic algorithms and a classifier system to build hierarchically-organized hybrid sorting algorithms capable of adapting to the input data. Our results show that such algorithms generated using the approach are quite effective at taking into account the complex interactions between architectural and input data characteristics and that the resulting code performs significantly better than conventional sorting implementations and the code generated by our earlier study. In particular, the routines generated using our approach perform better than all the commercial libraries that we tried including IBM ESSL, INTEL MKL and the C++ STL. The best algorithm we have been able to generate is on the average 26% and 62% faster than the IBM ESSL in an IBM Power 3 and IBM Power 4, respectively.
Benchmarks
 |
 |
|
Benchmark showing how our library improves sorting by dynamic adaptation to platform and input statistics [2]
|
Benchmark showing how dynamic algorithm selection improves sorting performance [1]
|
References
- Xiaoming Li, María J. Garzarán and David Padua
Optimizing Sorting with Genetic Algorithm
Proc. International Symposium on Code Generation and Optimization (CGO), pp. 99-110, 2005 - Xiaoming Li, María J. Garzarán and David Padua
A Dynamically Tuned Sorting Library
Proc. International Symposium on Code Generation and Optimization (CGO), pp. 111-124, 2004
Copyrights to many of the above papers are held by the publishers. The attached PDF files are preprints. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright. These works may not be reposted without the explicit permission of the copyright holder. Some links to papers above connect to IEEE Xplore with permission from IEEE, and viewers must follow all of IEEE's copyright policies.
More Information
Contact: Xiaoming Li, xli at ece.udel.edu